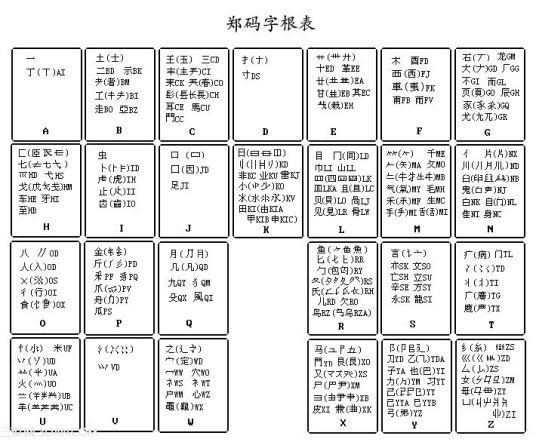
首先说,郑码现在用的人很少。不常用。《郑码》简称《字根通用码》,是我国著名文字学家、享誉海内外的《英华大词典》主编郑易里教授经半个世纪对汉字字形结构的研究,后期和郑珑高级工程师共同创造的重大科技成果。已获中、美、英国专利授权,并通过国家级的鉴定。权威专家们确认《郑码》是国内最优秀的字形编码系统。《郑码》规范、易学、快速、通用。用同一编码规则不但可以输入2万汉字,还可以输入68000个和10万个汉字。《郑码》曾荣获北京国际发明金奖和最优秀发明大奖;荣获第22届日内瓦发明金奖。国家主管部门通过评比向国内外用户广泛推荐《郑码》。中国的中文之星等系统平台选用《郑码》,美国Microsoft公司的Windows95/98/NT/2000/XP/Vista中文系统选用《郑码》,美国IBM公司的OS/2和JAVAOS等许多中文产品也都选用《郑码》。《郑码》以单字输入为基础,词语输入为主导,用2-4个英文字母便能输2字词、多字词和30个字以内的短语;在这种字词交融输入之下,输入一个汉字的平均码长是1.8-1.9键之间。他备有两个词库,分别收录25000和50000条词语。《郑码》是一种繁体字输入法,也是一种生僻字输入法,当然它也是一种常规输入法。郑码可以打出国标扩充字库(原来叫GBK字库,后来发展为GB18030字库)里的2万多个汉字,极大满足了人们在日常生活、工作中使用汉字的需求。在常规情况下,《郑码》输入法可以打出GBK字库里的20902个汉字。比普通《五笔字型》能打出的6763个汉字要多打出14139个汉字。正因为这个原因Windows没有预装《五笔》,而是预装了《郑码》输入法。基根位码的确定[编辑本段]每一根区里都有几个基根,它们的区码都相同,在它们单独成字或与其它基根组合成字时,会产生许多重码字。为解决这一问题,《郑码》规定:第一主根的代码用区码的1个字母表示,第二主根和副根型缓的代码都要用“区码+位码”2个字母表示,即在区码后面扩充一个位码,这种安排使得每个基根都有了独立的代码,从而解决了重码问题。就象每个人有姓有名才不会有太多的重名一样。《郑码》的编码规则[编辑本段]第一条:要按照《郑码》的基本字根总表上所列出的基根(包括形近根),把汉字分解成基本字根才能编码。如果没有合适的基根,就要进一步分解成笔画。例如:补--衤卜恳--艮心滤--氵虍心书--乛�丨丶第二条:汉字分解后,基根和笔画排列的顺序叫做“根序”。根序的确定有三种情况:l.左右字、上下字以及由单笔画组成的字,根序与规范的书写顺序一致(见上例中的“补、恳、滤、书”四个字的分解)2.具有相接、交叉和相嵌结构的字,第一笔先写的基根或笔画排列在前。例如:([]方括号内是例字)相接结构的字:夭--丿大[沃笑];疋--乛止[蛋疏];交叉结构的字:束--木口[整辣];夷--大弓[姨];屯--七凵[纯钝吨];相嵌结构的字:亘--二曰[桓恒];佥--人二(横三点)[检验]渊--氵(撇-竖)米;肃--肀(撇-竖)八[萧箫]复合结构的字:决--冫乛大[缺炔](又有相接又有相交);3.对于包围字和包孕字,要将第一笔先写的基根排在第一位。因为是以基根为单位排列根序。例如:困—囗木闻—门耳函—乛氺凵式—弋工载—�车库—广车匦—匚车九赵—走乂但卜颤模是,为了检索的快捷和归纳的划一,对于有“辶、廴”的字,确定根序时,要将“辶、廴”排列在洞高第一位。例如:“达—辶大”、“延—廴丿止”。总之,给单字或词语编码,就是按照编码规则依次取基根的代码组成字词的编码。根序搞错编码也随之而错。因此,正确认识单字的根序十分重要。第三条:单字和词语的编码不能超过4个字母,因此要根据单字或词语中基根数的多少决定基根代码的取舍,这种取舍代码的方法叫取码方法(详见以下说明)。单字的取码方法[编辑本段]术语:“1码根”是指第一主根,因它的代码只用区码1个字母。“2码根”是指第二主根和副根,因为它们的代码要用区位码的2个字母。“取1码”的意思是只取该基根的区码。一、单字编码的取码原则1.单字首根(即第一个基根)的代码要按照实际码数取,不能有所省略。就是说,首根是1码根就取1码;首根是2码根就取2码(区码和位码都要取)。2.为保证单字编码不超过4个字母,首根之后的其余基根代码要根据不同情况决定取舍。一般是先舍位码,只取区码的1码。例如:樱--木F贝LO贝LO女ZM--FLLZ醒--酉FD曰K生MC--FDKM但是,对于四基根和多基根字,还要将中间一些基根的代码全部舍弃,只取前两码和最末2个基根各1码。就是说,取两头舍中间。例如:缩--纟Z宀WD(亻)一A白NK--ZWAN糖--米UF(广)肀XB口J--UFXJ